
|
深度学习、机器学习与NLP的前世今生
专栏:科技资讯
发布日期:2018-11-27
阅读量:4121
一、为什么做文本挖掘什么是NLP? 简单来说:NLP的目的是让机器能够理解人类的语言,是人和机器进行交流的技术。它应用在我们生活中,像:智能问答、机器翻译、文本分类、文本摘要,这项技术在慢慢影响我们的生活。 NLP的发展历史非常之久,计算机发明之后,就有以机器翻译为开端做早期的NLP尝试,但早期做得不是很成功。直到上个世纪八十年代,大部分自然语言处理系统还是基于人工规则的方式,使用规则引擎或者规则系统来做问答、翻译等功能。 第一次突破是上个世纪九十年代,有了统计机器学习的技术,并且建设了很多优质的语料库之后,统计模型使NLP技术有了较大的革新。接下来的发展基本还是基于这样传统的机器学习的技术,从2006年深度学习开始,包括现在图像上取得非常成功的进步之后,已经对NLP领域领域影响非常大。 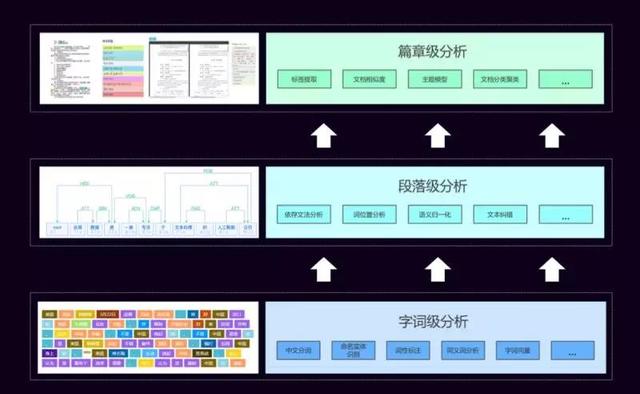 达观划分的NLP技术层次 当年上小学时有一本书叫《字词句篇与达标训练》,里面讲了字、词、句、篇,我们开始学写字,词是最基础的一级,中文的一个字比英文的一个字母的语义要丰富的多,但表义能力仍然较差。所以中文一般的处理情况都是按照词级别,词级别的分析就有了中文分词、有了命名实体识别这样的层次来做底层处理。 在这个底层处理之上是段落级别,是一句话、一段话、短的文本,对这个级别文本做法又对应了相关的技术,包括:依存文法分析、词位置分析、语义归一化、文本纠错等等功能。但是这个功能也是为它更上级的服务去服务的,达观称之为“篇章”级的应用。 大部分同学平时做比赛、做项目关注的点最多是在“篇章”级的应用,底下这些中文分词等都已经有很好的工具了,不用再从头到尾去开发,只要关心上层的应用,把底下的工具用好,让它产生需要的Feature,来做分类、主题模型、文章建模,这种比较高层次的应用。 所以,要做好NLP,包括我们公司在内,这三个级别的技术都是自己掌握的。但是如果个人学习使用是有权衡的。某个同学的某一个技术特别好也是OK的,因为现在开源工具,甚至商用工具有很好的效果。如果不要求精度特别高或者有特殊的要求,用这些工具一般是可以达到你的要求。 每个层次的技术都是完全不同的,而且层次间的技术是有联系,一般的联系是底层是为上层服务。 达观数据就是应用这些技术为企业提供文档智能审阅、个性化推荐、垂直搜索等文本挖掘服务。 二、为什么要用深度学习?深度学习的发展与应用要有一定的基础,上个世纪末互联网时代到来已经有大量的数据电子化,我们有海量的文章真是太多了。有这样的数据之后就要去算它,需要算法进步。以前这个数据量规模没法算,或者数据量太大算起来太慢。就算有更好的算法还是算得很慢时,就需要芯片的技术,尤其我们现在用并行计算GPU,这个加速对各种各样的算法尤其深度学习的算法影响速度非常大。 所以一定要有这三个基础——数据、算法、芯片,在这三个核心基础上面做更高级的应用,涉及人的感官——听觉、视觉、语言这三个感官,语音的识别、计算机的视觉、自然语言的处理。 1. 深度学习与机器学习很多同学会把深度学习和机器学习划等号,实际上它们不是等号。AI的概念非常大,比如:我们用的Knowledge Base知识数据库也是一种AI,它可能没有那么智能。机器学习是AI其中的一小块,而深度学习用又是机器学习中的一小块,我们常见的CNN、RNN都属于深度学习的范畴。 同时,也做Logistics Regression知识图谱,因为知识图谱是NLP中一个很重要的应用,无论是生成知识图谱,还是用它做像问答等其他应用都是会用到的。 我们为什么要用深度学习? 可以比较一下经典机器学习和深度学习间的差异。 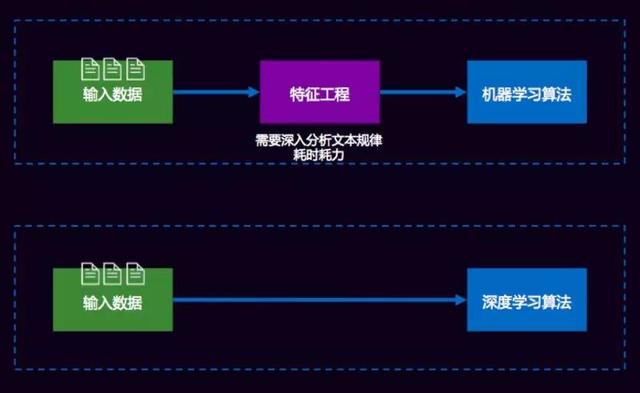 比如:做一个分类的问题,这两个分类问题唯一的区别就是特征工程的区别。我们用经典的机器学习算法是上面这条路,输入数据后大家就开始(包括打比赛也)做各种各样的特征工程。有了这样的特征,我们还要根据TF-IDF、互信息、信息增益等各种各样的方式去算特征值,或对特征进行过滤排序。传统机器学习或经典机器学习90%的时间,都会花在特征工程上。 而Deep learning颠覆了这个过程,不需要做特征工程。需要各种各样的特征,比如:需要一些长时间依赖的特征,那可以用RNN、LSTM这些,让它有个序列的依赖;可以用局部的特征,用各种各样的N元语法模型,现在可以用CNN来提取局部的文本特征。 深度学习节省的时间是做特征工程的时间,这也是非常看重深度学习的原因:
有了深度学习之后,对文本挖掘就有了统一处理的框架,达观把它定义为五个过程: 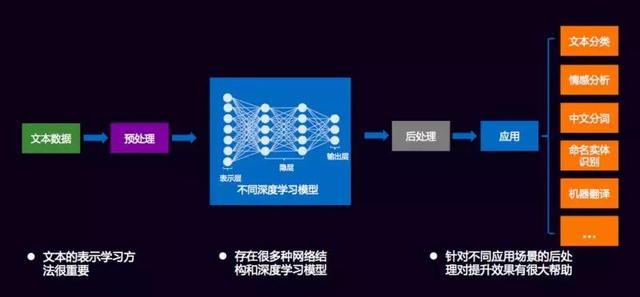
几乎所有任务都可以拿Deep learning来做,它的适应性和它的广度非常好,例如:传统的机器学习做文本分类需要特定的算法,而这个算法不可能做命名实体识别的事情。 2. 通过Vector Representationns 进行低纬度连续空间的字词表示在深度学习在NLP领域火起来之前,最有代表性的一个研究,对每个人影响最大的工作就是Word2Vec,把一个字、一个词变成向量来表示,这是对我们影响非常大的工作。 这件事情的好处是什么? 在之前我们以词为单位,一个词的表示方式几乎都是one hot。 one hot序列有一个致命的缺点,你不能计算相似度,所有人算出来都是“0”,都是一样的,距离也都是一样的,因此它不能很好的表示词之间的关系。 过去像威海市、潍坊市、枣庄市这三个城市对计算机来说是完全不一样的东西,而我们使用Word2Vec做这件事情有两个好处: 第一,这个词如果有1万维的话,1万维本来存储它就是一个非常稀疏的矩阵、而且很浪费,我们就可以把它变得更小,因为我们的Word2Vec里面一般的向量都在 512以内。 这个维度的向量相对1万维来说已经是比较低维的空间,它里面存的是各种的浮点数,这个浮点数看起来这三个向量好像每个都不一样,但是实际去计算,发现这三个向量之间的相似度非常高,一个是相似度可以判断它的相似性,另外是判断它们的距离。 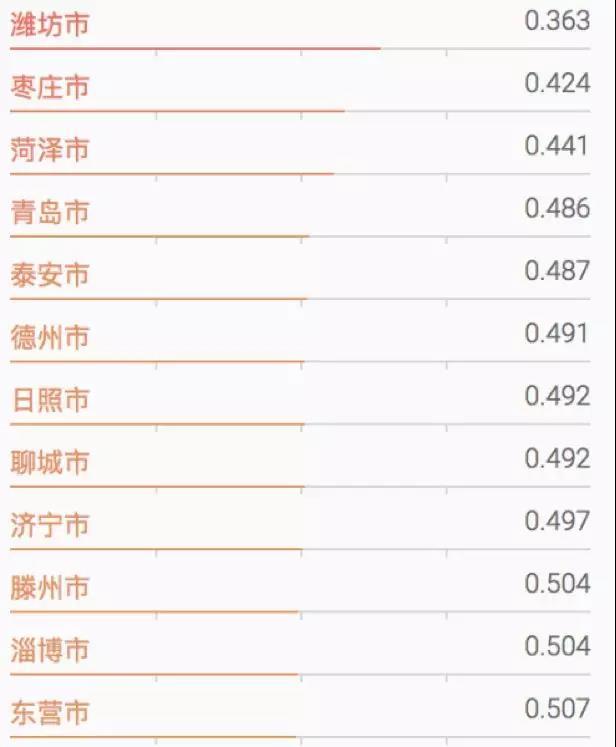 威海、潍坊、枣庄这几个城市在空间上离得非常近,它们的数值也非常近。它对于我们实际工作的好处是增强了我们的泛化能力,这是一个很难做的事情。
有了表示学习之后,下一步就是常见的各种网络结构,这些都是非常常见的,比如:CNN、GRU、RNN、Bi-LSTM。LSTM也是一种RNN,Bi-LSTM也是一种LSTM,只不过Bi是双向的LSTM,它可能学到前后上下文的特征和语义。 GRU的好处是比LSTM这种算法稍微简单,所以在层次比较深的时候或者比较复杂的时候,用它这个单元的运算效率会高一点、快一点,但它实际精度可能稍微差一点。所以模型那么多,怎么来选是很重要的,要根据大家的实践去看看怎么用。 3. CNN模型原理CNN是卷积神经网络。 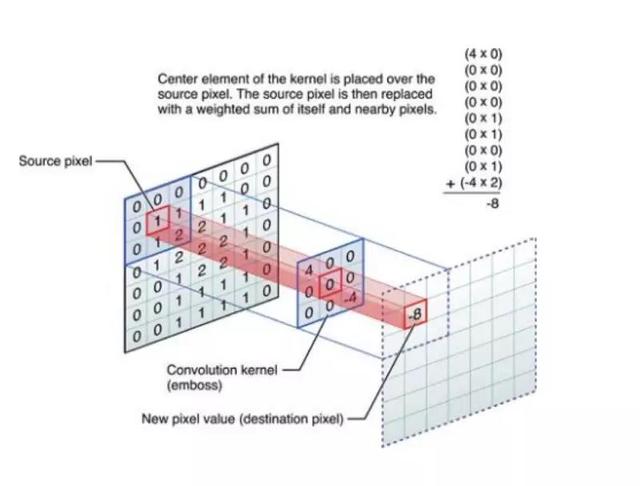 这张图中间的九宫格就是个卷积格,每个数字相当于一个过滤器。它做的事情对一个图像来说,是把九宫格和图像中对应的矩阵相乘,乘出来一个结果,得到卷积之后它就开始平移,平移的步长是可选择的,一般我们都是一步一步平移过去。 它这样的好处是什么?对于图像来说,1个像素真的代表不了什么东西,那9个像素是不是有意义? 是有意义的,它可能学到像直线、弯曲等特征,很简单的图形特点,然后它会得到一层。 为什么叫深度学习? 我们这只是一层,它在CNN里面尤其图像识别网络,大家都听过“大力出奇迹”,网络越深效果越好,因为它经过一层一层的学习,可以把每一层的特征进行浓缩。 简单的像素没有任何的表义能力,到第一层浓缩之后它有一些点线的能力,再往上浓缩可能就有弧线的能力,再往上浓缩它越来越复杂,可以做到把一个像素这个没有意义的东西变成有意义的东西。可以它可以看成是一层层的过滤,选出最好的特征结果,这是卷积的原理。卷积不仅仅在图像里,在文本里用得也非常好。 4. RNN和LSTM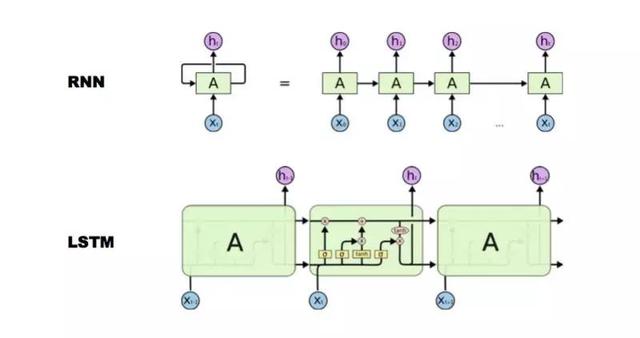 简单来说LSTM就是单元格换了一个更复杂的RNN,它可以做到RNN做不到的事情。 为什么叫长短期记忆网络? 看下面这张图,它比传统的RNN多了一个所谓的细胞状态,我翻译成“细胞”,一般也叫“cell”,它多了一个存储长期信息的“cell”状态。 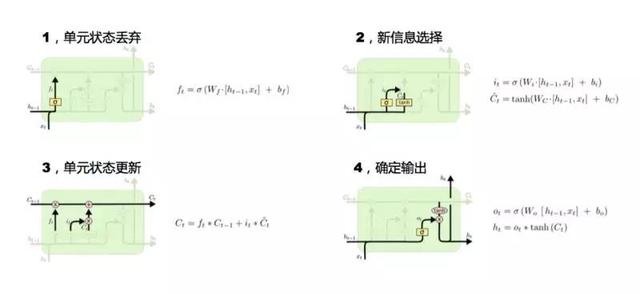 我们看一下第一张图,它是怎么来做长期记忆的更新? 看输入Ht-1和Xt,Ht-1是上一个时刻这个cell隐状态的输出,Xt是当前输入,它们两个通过这个函数计算后的输出是0-1之间的某一个值。
有了第一步和第二步之后就开始第三步细胞状态更新,第一步的输出0-1和Ct-1相乘决定上一时刻这个细胞状态留下多少。第二步算出来系数和信息量相乘决定留下多少新增信息,然后把上一步剩下的和这一步新增的加起来,做一个更新,这个更新就是现的cell状态值。 现在单元的状态更新完了,下一步就要输出,这个输出有两个:第一个,对外是一样,还是隐层的输出Ht,这个输出和前面讲的RNN隐层输出是一样的,只是多了一步内部更新。决定留下多少老的信息,决定留下多少新的信息,再把老的信息和新的信息加起来就是最终的结果。 长短期记忆网络可以把很长很远的语义通过Ct把信息记下来,而RNN本来就很擅长记忆这种比较近的信息,所以LSTM长短信息都能记下来,对后面特征的选择、模型的输出选择有很大的帮助。 三、深度学习的具体应用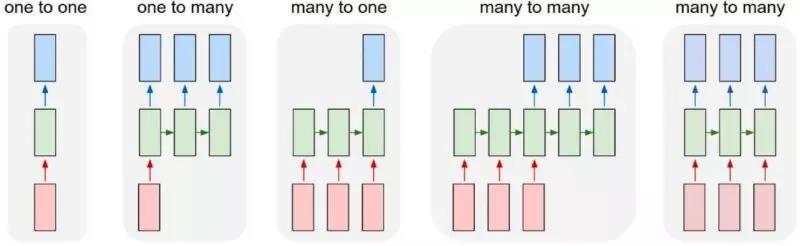
本次讲的是文本,所以我着重会讲many to one和many to many的过程。 1. 文本分类 “达观杯”算法大赛很多同学在用传统的方式,包括baseline来做,很多人吐槽baseline好像有点高。但是我们没有做特殊优化,这是最基础的版本,做出来很高说明传统的机器学习还是非常好的,不是Deep learning一统天下。 传统的机器学习,需要构造特征,不同领域定制化程度很高,这个模型A领域用了,B领域几乎要从头再做一遍,没有办法把其他的特征迁移过来很好的使用。某些领域效果很好,某些领域另外一个算法很好,传统机器学习把各种各样的方式做以融合来提升效果。 深度学习则可实现端到端,无需大量特征工程。框架的通用性也很好,能满足多领域的需求,并且可以使用费监督语料训练字词向量提升效果。 但是为什么有人吐槽Deep learning? 因为调参很麻烦,有时改了一下参数好很多,改了一个参数效果又下降了,有的算法能够对此有一定的解释,但不像传统机器学习能够解释得那么好。这两大帮派不能说完全谁战胜了谁,是相融相生的。 2. TextCNN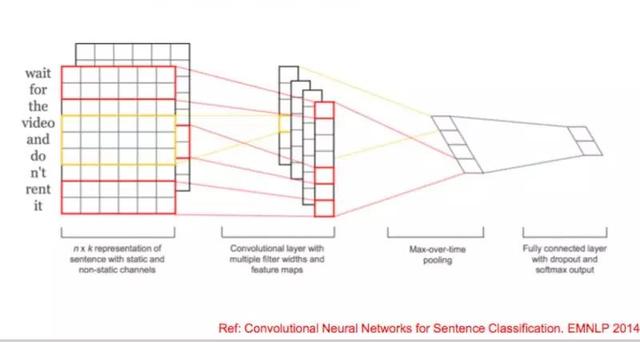 它是一个单层的CNN,选择了几种类型的卷积,做一个feature map,然后用max-pooling取得每个map最大的特征作为最终的输出,结构非常简单,大家只要有一点深度学习的知识就可以。但是因为过于简单,而且CNN天生的缺陷是宽度有限,导致它会损失语义的问题。 2. Deep Pyramin CNNDeep Pyramin CNN就是深度的CNN, CNN的特点就是结构简单。虽然有block N,但它每个block长得都是一样的,除了第一层,每一层就是一个pooling取一半,剩下是两个等宽度的卷积,输出250维,叠加好几层后就可能学到非常准的语义。 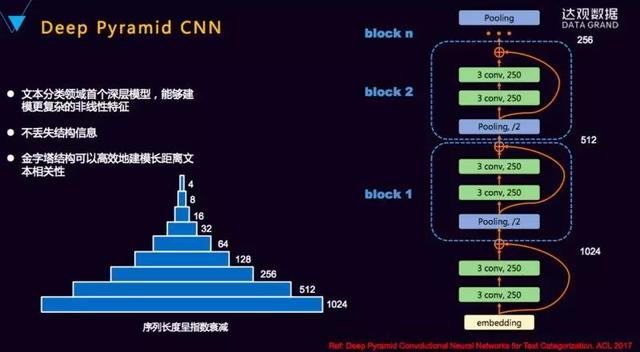 3. Hierarchical Attention Network这个模型的优点是非常符合人类的思维。Word级别的时候前面的套路都是一样的,做各种Embedding,在Embedding到下一层次,这个输到下一层sentence级别之前会加一层Attention,让它知道这句话里面哪一个词最重要,这像我们知道一句话中哪个词最重要。 最终输出之前再加个Attention,这个Attenton去学这里面哪些句子最重要的。你可以简单的理解,它把我们输入的那么多文本,也是经过了一层层的过滤,前面是通过卷积的过程,它现在是通过Attention的机制去找。 还有一个特别好的地方是学部分可解释,句子里哪些词最重要,它的蓝颜色就更深,它能找到语义级别哪个语义对分类贡献最大,这是这个网络很好的一点。 包括前面讲的HNN、Deep Pyramin CNN,网上的实现跟论文是有一定差别的。所以大家要注意,我们关注的是它整体的网络结构,并不是每一点的百分之百的还原,我们不是它的复制者,而是它的使用者。所有的网络结构、参数甚至过程,只要大体的思想有了就OK。这两个是many to one在文本分类上用得很多的。 4. 序列标注序列标注就两个东西:第一个是定义标签体系。我们这边一般最常用BMES,简单一点的IO,复杂一点的BIO,BMES算是一个经典的方法,不多也不少,还有M1、M2、M3更复杂的一般都不太用。 5. 深度学习和传统文本处理方法的结合传统的CRF用起来效果不错,Deep learning也能够把这个事情做得很好。LSTM可以学习到很长的上下文,而且对识别非常有帮助。实际问题或者工业应用来说,我们要保证它的整体效果和复杂度的情况下,这边Bi-LSTM是一个非常好的方式,也是相对比较成熟的方式。 为什么要加CRF? 我对这个模型结构的看待,它是一个深度学习和传统方式非常完美的结合。Bi-LSTM做特征工程,CRF做标签的输出。很多同学都试过,用纯的Bi-LSTM去写,最终输出标签之间没有序列依赖的关系。 6. 序列标注特征选择多维度字词向量表示做这个模型能做什么事情?大家的网络都类似,怎么去PK? 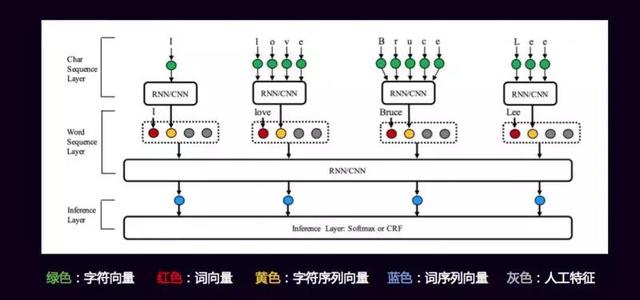 这是非常好的一篇论文,讲到了我们怎么能够把各种各样的level的信息用到,它这边是英文,所以有一个char级别的,先对char,通过RNN、CNN做一个Embedding。学习到char级别上的关系,char级别的关系合并之后是黄颜色那个字符的向量,然后它又把word级别的红颜色的词向量也加进去拼起来,还有两个是灰颜色的,灰颜色的是人工特征。就看大家自己怎么加,这是每个人的智慧。 7. 引入注意力机制来实现生成式摘要生成式摘要是很难的一个东西,它的训练集标注比我们标分词、标分类难得多,要有一篇文章,人得写出摘要,整理出好多这样的摘要。因为每个人写得不一样,包括评测的方式BLUE等,所以做摘要比较难。但是我们平时可以基于生成式文本的其他小应用。 举个简单的例子:大家爬过一些新闻的网站,那么长的正文一般正文第一段把事情都说清楚了,然后有一个新闻的标题,我们可以用第一段作为输入,标题作为输出,做这样一个简单的通过新闻第一段可以写出新闻标题的功能,其实跟生成摘要的思想是一样的。唯一的差别是它加了注意力的机制,会发现它关注输出的哪些词对语义表达最有用,它会关注有用的信息,解码的时候就可以得到各种各样的序列、各种各样的值,用beam search找到最好的结果。 引入注意机制,以前做不了这个事情,现在我们可以做这个事情。工业中用得比较多的是抽取式的摘要。简单来说,就是一篇文章中哪些句子比较重要,把它抽出来就可以了。 四、文本挖掘的经验和思考实际工程中需要考虑的因素
实际工程中运用深度学习挖掘文本的思考深度学习优点: 我们可以用非监督的训练向量来提升它的泛化,主要目标是提升泛化。它有些端到端的方式,可以提供新思路。 深度学习能够克服传统模型的缺点,大家用CRF很多,但CFR有时拿不到太远的长的上下文,它比较关注左右邻居的状态,很远的状态对它影响不大。 但是有些语义影响很大,比如:我们要抽“原告律师”、“被告律师”、“原告刘德华”,然后中间讲了一大堆,“委托律师张学友”,我们能抽取出来他是律师,但是如何知道他是原告律师? 一定要看到刘德华前面三个有“原告”两个字,才知道他是原告律师。这时如果用深度学习LSTM的方式可以学到比较远的上下文特征,帮助你解决这个问题。 深度学习缺点:
思考:
下一页:人工智能的两种路线之争
说点什么
发表
最新评论
|





点击开启品牌新篇章

爱用建站是智能网站SAAS平台。通过集成前沿云计算技术和丰富优质电商应用,爱用建站为用户一站式提供运营简单、功能强大、自带流量、灵活拓展的全网智能网站。任何人无需技术都可以轻松拥有。

网站支持
增值电信业务经营许可证编号:B2-20150988

