
有句话叫作,你能看见多久的历史,就能看见多远的未来。让我们首先简单回顾一下互联网和人工智能之间的历史风云。
大家对于互联网的历史多少已有耳闻。互联网于 20世纪 60年代诞生于美国军方的实验室,一开始用来在几所高校和科研机构之间传递和共享情报。到了 20世纪 80年代末,一群科学家提出万维网概念并创造了 TCPIP(互联网传输控制协议),赋予计算机联网通信的统一标准,使互联网得以向全世界扩展。至此,一条宽阔深远的信息高速公路展现在世人面前。
大约 20年前, 23岁的年轻人马克 ·安德森发明了网景浏览器,就此点燃了大众互联网的熊熊火焰,打开了互联网商用的大门。那时,微软开始焦虑自身的软件业务会不会被互联网颠覆,太阳公司的年轻人则毅然与僵化的公司割裂,决定发明一种可以在各种操作系统上通用的语言,以此打破微软的垄断,闯开互联网创新之门,于是就有了 Java(程序设计)语言的诞生。 Java语言极大地加速了互联网产品的开发创造。
当时的中国,在北京、上海也还找不到几家网吧, 1997年,也就是香港回归的那一年,瀛海威刚刚开通全国网络接入服务,张小龙刚刚写出了 Foxmail电邮软件程序,全国信息化工作会议也在那一年召开……从外面看万维网世界,一切都是刚苏醒的模样。但在技术圈,新技术、新思想层出不穷,各种商战明争暗斗正酣。
回想网景、太阳、微软这三家公司在互联网领域类似三国争雄般的时代,至今依然激动不已。当时人们都在猜测谁是最后的赢家。微软看上去好像是不可战胜的,它总是能消化新技术。网景的发展则是起起伏伏,最终被美国在线收购,而美国在线也在 2014年被以无线业务称雄的 Verizon(威瑞森)公司收购。后来, Verizon还收购了叱咤风云多年的雅虎。太阳公司一度如日中天, 2001年在全球拥有 5万名雇员,市值超过 2000亿美元。然而当互联网泡沫破碎时,太阳公司在一年内由峰顶跌入谷底, 2009年被 Oracle(甲骨文)公司收购。
俱往矣,互联网的发展大大超出了当时大多数人的预料,新科技公司快速崛起,苹果、谷歌终于凭借手机操作系统完成了对微软的逆袭。而创造网景浏览器的马克 ·安德森——我在《硅谷商战》开篇就描摹的创新者,如今已没有多少 90后知道他的名字。
但马克·安德森并没有离开,他成了硅谷风投界的教父。互联网技术也依然继续高歌猛进。昔日人们关注互联网大咖明争暗斗,今日人们感慨移动互联设备全面超越 PC,却一直无意中冷落了一个默默崛起的“幽灵”。这个“幽灵”就是人工智能,互
联网只是它的身体之一。
人工智能的黎明
人工智能的历史早于互联网,与计算机历史相伴。 1956年达特茅斯会议召开,人工智能被正式提上日程。那时候一台计算机的体积有一栋房子那么大,计算能力低下,为什么就有人敢于提出人工智能的概念?这就在于科学家的洞察力。当时,香农早已完成他的三大通信定律,为计算机和信息技术打下基础。明斯基已经造出第一台神经网络计算机(他和同伴用 3000个真空管和一台 B-24轰炸机上的自动指示装置来模拟 40个神经元组成的网络),不久后写出了论文《神经网络和脑模型问题》。这篇论文在当时没有太受重视,日后却成为人工智能技术的鼻祖。而图灵则早在 1950年就提出了如今人尽皆知的图灵测试理论以及机器学习、遗传算法、强化学习等多种概念。
图灵去世两年后,在达特茅斯会议上,麦卡锡正式提出人工智能的概念。参与会议的十位年轻科学家在会议之后都成为世界各国人工智能领域的领军人物。人工智能短暂的春天开始了。不过当时他们的成绩更多被埋没在计算机发展成果之中,比如,可以解决闭合式微积分问题的程序,搭建积木的机械手等。
理想超前但基础设施尚在襁褓中。超前的人工智能遇到两个难以克服的瓶颈:一个是算法逻辑自身的问题,也就是数学方法的发展还不够;另一个是硬件计算能力的不足。比如,机器翻译就是典型问题,科学家夜以继日地总结人类语法规则,设计计算机语言模型,机器却始终无法把翻译准确率提升到令人满意的程度。

图 1-1达特茅斯会址
新技术和产业链条没有被打通,令人兴奋的产品应用没有被发明出来,政府投资和商业投资都大幅度减少,人工智能研发在 20世纪 70年代中期到 90年代经历了两次低潮,只是普通大众并没有感受到,毕竟高速发展的计算机本身就已经是很神奇的智能工具了。
对于普通人来说,接触最多的“人工智能”实例大概就是街机游戏了, 20世纪 80年代在中国的一些小县城街头就已经出现了游戏厅。那些街机 NPC(非玩家控制角色)总是能被熟练玩家轻松战胜,这不仅可以看作“人工智能”能力低下的表现,也造成了一种错误观念:智能是安装在一台计算机中的事物。直到互联网和云计算的兴起,这种观点才被改变。
百炼成钢
2012年,深度学习在学术界和应用方面都有了突破。比如,用深度学习的方法来识别图像,突然就比以前的任何算法都有明显提升。新的时代来临了,搜索将被革新。过去我们用文字搜索,现在可以用语音和图像进行搜索。比如我看到一株不认识的植物,拍一张照片上传搜索,就可以立刻识别出来它叫福禄桐。过去用文字搜索是没法描述这样的植物的。不仅是搜索,很多过去不可能的事情现在都可能了。
语音识别能力、图像识别能力、自然语言理解能力,包括为用户画像的能力,这些都是人的最本质的智慧能力。当计算机拥有了人的这些能力时,一场新的革命就会到来。以后速记员和同声传译人员可能会被机器代替,计算机可以做得更好。以后也许不需要司机了,车自己就可以开起来,更安全,更有效率。在企业里面,金牌客服可能人人都可以做了,因为有了智能客服助手。人工智能对人的这种赋能,超过了以往任何一个时代。工业革命解放了人的体力,过去一些像搬石头之类的粗活需要人类自己来干,现在机器可以替你把更巨大的石头搬起来。智能革命到来之后,原本很多需要费脑子的事情,机器也可以帮你做。未来 20~50年,我们会不断看到各种各样的变化,收获各种各样的惊喜。这是一个很自然的过程。然而,站在智能革命开始的时点,有必要向那些人工智能科学的坚守者、开拓者致敬。在资本寒冬期,有少数科学家依然坚持人工智能领域的探索。
如今百度拥有一支庞大且实力雄厚的人工智能研究团队,其中不少担纲者从 20世纪 90年代开始就在从事机器学习研究工作,或师从名师,或在大科技公司从业多年,今天的研发成绩只是水到渠成、顺势而为的结果。
20世纪 90年代只有 Geoffrey Hinton(杰弗里·辛顿)、 Michael Jordan(迈克尔·乔丹)等少数科学家坚持机器学习领域的探索。原百度首席科学家吴恩达在 20世纪 90年代就师从 Jordan,后来他通过开创在线课程,把机器学习的理论传授给无数年轻人。现任百度研究院院长林元庆,百度杰出科学家以及世界上最早利用神经网络做语言模型的徐伟等人,十多年前就在深度学习的重镇 NEC(日本电气股份有限公司)的美国实验室工作。在那里工作过的人工智能专家,有发明 SVM
(Support Vector Machine,支持向量机)的美国工程院院士 Vladimir Vapnik(弗拉基米尔·瓦普尼克),有发明卷积神经网络的深度学习领军人物、现任脸书( Facebook)人工智能实验室主管的 Yann Le Cun(扬·勒丘恩),还有深度学习随机梯度算法的核心人物 Leon Buttou(利昂·布托),以及原百度深度学习实验室主任余凯等。
他们中的很多人都经历了人工智能研究的数次潮起潮落。简单来说,最初的人工智能研究大多基于规则——人类总结各种规则输入计算机,而计算机自己并不会总结规则。比这个高级的方法是基于“统计”的机器学习技术,让计算机从大量数据和多种路径中寻找概率最大、最合适的模型。
这两年促使人工智能再度技惊世人的技术,则是机器学习技术的升华版——基于多层计算机芯片神经网络的“深度学习”方法。通过多层芯片联结,模仿人脑大量神经元的网状联结方式,辅以精妙的奖惩算法设计和大数据,可以训练计算机自己从数据中高效地寻找模型和规律,从而开启了一个机器智能的新时代。
正是少数人的坚持,为人工智能的王者归来保存了火种。在中国,百度是最早布局人工智能的公司之一,我们似乎是自然而然地做了很多其他公司当时还没听过的事情。六七年前,在美国,陆奇和我畅谈了深度学习的巨大进展。于是我们下定决心要大举进入这样一个领域。最终,在 2013年 1月,百度年会上我正式宣布了 IDL(深度学习研究院)的成立,这应该是全球企业界第一家用深度学习来命名的研究院。我自任院长,不是因为我比其他人更懂深度学习,而是用我这块牌子,来展示对深度学习的高度重视,来召唤那些坚守多年的科学家一起奋斗。
过去百度从不专门成立研究机构,我们的工程师就是研究人员,研究始终与实际应用结合得非常紧密,但是我认为,深度学习会在未来很多领域产生巨大影响,而那些领域并不都是百度现有业务范围之内的。所以,有必要创造一个专门的空间,把人才吸引进来,让他们能够自由发挥,去尝试各种各样的创新,在百度过去可能从来没有接触过的领域做研究,为全人类的人工智能革命探索道路。
“智能”已换代
如果人工智能的启蒙阶段可以称为 1.0时代的话,那么现在很明显已经大步进入 2.0时代了,机器翻译就是典型案例。过去的机器翻译方法就是基于词和语法规则进行翻译——人类不断地把语法规则总结出来告诉机器,但却怎么也赶不上人类语言尤其是语境的多变,所以机器翻译总是会出现诸如把“how old are you”翻译成“怎么老是你”的笑话。
后来出现了 SMT(统计机器翻译),基本思想是通过对大量的平行语料进行统计分析,找出常见的词汇组合规则,尽量避免奇怪的短语组合。 SMT已经具有机器学习的基本功能,有训练及解码两个阶段:训练阶段就是通过数据统计让计算机构建统计翻译模型,进而使用此模型进行翻译;解码阶段就是利用所估计的参数和给定的优化目标,获取待翻译语句的最佳翻译结果。
SMT研究在整个业界已经持续了二十多年,对于短语或者较短的句子,翻译效果显著,但是对于较长的句子翻译效果就一般了,尤其是对语言结构差异较大的语言,例如中文和英文。直到近几年 NMT(基于神经网络的翻译)方法崛起。 NMT的核心是一个拥有无数结点(神经元)的深度神经网络,一种语言的句子被向量化之后,在网络中层层传递,转化为计算机可以“理解”的表达形式,再经过多层复杂的传导运算,生成另一种语言的译文。
但是应用这个模型的前提是数据量要大,否则这样的系统也是无用的。像百度和谷歌这样的搜索引擎,可以从互联网上发现和收集海量的人类翻译成果,把如此巨大的数据“喂给” NMT 系统, NMT系统就可以训练和调试出比较准确的翻译机制,效果要好于 SMT。中文和英文之间的双语语料信息储备越多, NMT的效果就越好。
SMT以前用的都是局部信息,处理单位是句子切开以后的短语,最后解码时将几个短语的译文拼接在一起,并没有充分利用全局信息。 NMT则利用了全局信息,首先将整个句子的信息进行编码(类似人在翻译时通读全句),然后才根据编码信息产生译文。这就是它的优势,也是其在流畅性上更胜一筹的原因。
比如,翻译中有一个很重要部分是“语序调整”。中文会把所有的定语都放在中心词前面,英文则会把修饰中心词的介词短语放在后面,机器常混淆这个顺序。 NMT在语序学习上的优势带来了它翻译的流畅性,尤其在长句翻译上有明显优势。
传统的翻译方法也不是一无是处,每一种方法都有其擅长的地方。以成语翻译为例,很多时候有约定俗成的译文,不是直译而是意译,必须在语料库中有对应内容才能翻译出来。如今互联网用户的需求是多种多样的,翻译涉及口语、简历、新闻等诸多领域,一种方法很难满足所有的需求。因此百度一直把传统的方法如基于规则的、基于实例的、基于统计的方法与 NMT结合起来向前推进研究。
在这种机器翻译的模式中,人类要做的不是亲自寻找浩繁的语言规则,而是设定数学方法,调试参数,帮助计算机网络自己寻找规则。人类只要输入一种语言,就会输出另一种语言,不用考虑中间经过了怎样的处理,这就叫作端到端的翻译。这种方法听起来挺神奇,其实概率论里的贝叶斯方法、隐马尔科夫模型等都可以用来解决这个问题。
以资讯分发当中的贝叶斯方法为例,可以构建一个用概率来描述的人格特征模型。比如男性读者模型的特征之一是在阅读新闻时点击军事新闻的概率是 40%,而女性读者模型是 4%。一旦一个读者点击了军事新闻,根据图 1-2 中的贝叶斯公式就可以逆推这个读者的性别概率,加上这个读者的其他行为数据,综合计算,就能比较准确地判断读者的性别以及其他特征。这就是数学的“神奇”。当然,计算机神经网络使用的数学方法远不止这些。
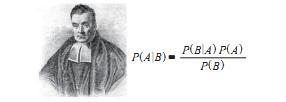
图 1-2 贝叶斯与贝叶斯公式
类似机器翻译的人工智能技术方法的前提是数据量足够大。互联网提供了以前科学家梦寐以求却难以得到的海量数据。互联网诞生的初衷是为了信息沟通方便,结果带来了信息爆炸,信息爆炸又促进了人工智能技术的发展。
再以下棋为例。1952 年瑟·萨缪尔编写了跳棋程序,水平能达到业余高手程度。跳棋规则比较简单,计算机在这方面有人类很难比拟的优势,但是国际象棋就难多了。百度总裁张亚勤在微软担任研究院院长的时候,请来中国台湾计算机才子许峰雄,他在 IBM(国际商业机器公司)的时候开发了名噪一时的国际象棋机器人“深蓝”。20世纪 90年代的人工智能代表非“深蓝”莫属,“智慧”集中在一台超级计算机上[使用了多块 CPU(中央处理器)并行计算技术],连续战胜人类国际象棋高手,并终于在 1997年战胜了人类国际象棋冠军卡斯帕罗夫。不过富有意味的是,比赛之后不久, IBM就宣布“深蓝”退役了。张亚勤对许峰雄说,“你去做围棋吧,等能下赢我的时候再来找我”,但直到他离开微软,许峰雄都没有再来找过他。
“深蓝”本身面临一些无法突破的瓶颈,虽然可以处理国际象棋棋盘上的运算,但面对围棋棋盘上达到宇宙数量级变化的可能性,只能望洋兴叹。基于决策树算法,穷举一切走子可能性的模式超出了计算机的承载能力,虽然算法不断优化,但还是无法突破计算瓶颈。以围棋为代表的东方智慧,面对人工智能似乎可以稳若泰山,但一个新时代正在来临。







